
The following points highlight the top four types of tests of significance in statistics. The types are: 1. Student’s T-Test or T-Test 2. F-test or Variance Ratio Test 3. Fisher’s Z-Test or Z-Test 4. X2-Test (Chi-Square Test).
Test of Significance: Type # 1. Student’s T-Test or T-Test:
It is one of the simplest tests used for drawing conclusions or interpretations for small samples. This test was worked out by W.S. Gosset (pen name “Student”), f-test is used to test the significance of means of two samples drawn from a population, as well as the significance of difference between the mean of small sample and hypothetical mean of population (expressed in terms of standard error).
(I) Application of t-test for assessing the significance of difference between the sample mean and population mean:
The computation of t-value involves the following steps:
(i) Null Hypothesis:
First of all, it is presumed that there is no difference between the mean of small sample and the population means (µ) or hypothetical mean. Thus,
Null hypothesis (Ho): sample mean (X̅) = population mean (µ) or Ho = X̅ = µ
(ii) Test statistics:
T-value is calculated by the following formula:

(iii) Degree of freedom:
It is one less than the number of units in the sample.
Degree of freedom (d.f. or v) = No. of units in the sample – 1
= n – 1
(iv) Level of significance:
Any level of significance can be considered to test the hypothesis but generally 1 % (=0.01) or 5% (= 0.05) levels of probability is considered for testing the hypothesis.
(v) Table value of t:
After calculating the value of (= t – cal) with the help of above formula, the value of t is noted from Fishers and Yates Mable at given degree of freedom and 5% level of significance. Then after the calculated value of t is compared with the table value of t.

(vi) Test criterion. If the calculated value of t (t-cal) irrespective of the positive (+) or negative sign (-) is less than the tabulated value off at respective degree of freedom and at 5% or 0.05 level of probability, then the Null hypothesis is correct, i.e., difference between the sample mean and population mean is insignificant and so the hypothesis is acceptable.
But, if the calculated value of t (- cal) is greater than the tabulated value of t (t-tab) at given degree of freedom and at 5% level of probability, then the observed difference is considered statistically non-significant and so the null hypothesis is incorrect and rejected.
In such a ease the observed data are not according to the expected data or in other words, the sample under test does not represent the population with µ as its mean.
(II) T-test for assessing the significance of the difference between the means of two samples drawn from the same population:
t- test is also applied to test the significance of the difference between the arithmetic means off two samples drawn from the same population.
The procedure of the test is as follows:
(i) Null hypothesis:
In this, first of all it is presumed that there is no difference in the standard deviations of the two samples under test, i.e.
HO = µ1 = µ2
where µ1 and µ2are the standard deviations of the sample I and sample II respectively.
(ii) Test statistics:
Next, the value of t is calculated by the following formula:

(iii) Degree of freedom:
(d.f.) = n1+ n2 – 2)
(iv) Level of significance:
The level of significance is generally considered at 5% (0.05) level «f probability.
(v) Tabulated value of t:
Value of t is recorded from the Fisher and Yates table at the given degree of freedom and at 5% level of significance.
(vi) Test criterion:
At last, the calculated value of t (|t|- cal) is compared with the table value of t at the given degree of freedom and 5% level of significance.
(a) If the calculated value of r-exceeds the table value, the observed difference is considered statistically significant and hence null hypothesis is rejected.
(b) If the calculated value of (|t|- cal) is less than the table value of t, the differences are not significant. Therefore, Ho hypothesis is accepted and the samples represent the population well.
Test of Significance: Type # 2. F-Test or Variance Ratio Test:
F-test was first worked out by G.W. Snedecore. This is based on F distribution and is used to test the significance of difference between the standard deviations of two samples. Snedecore calculated the variance ratio of the two samples and named this ratio after R. F. Fisher. Therefore, the test is referred to as f-test or variance ratio test.
The procedure F-test is as follows:
(i) Null hypothesis:
In this, it is presumed that the ratio of variance of two samples is not significant.
(ii) Test statistics:
Value of F is determined by the following formula:

Degree of freedom:
(d.f.) for sample I (v1) = n1-1 and d.f. for sample II (v2) = n2 – 1
The level of significance:
Generally the level of significance is considered either at 1 % (0.01) or 5% (0.05).
The tabulated value of F:
The value of F for a sample with greater spread at given d.f. is located in the Table from left to right and for the other sample with low spread at respective degree of freedom is located in the same table from top downward.
Where the two meet each other that value of given level of significance is F-value.
Now if the calculated value of F is less than the tabulated value of F then null hypothesis is true and accepted, i.e., the difference between the standard deviations of two samples is not significant and so the two samples under test might have been drawn from the same population.

If the calculated value of F is, however, greater than the table value of F (F – cal > F-tab.) the null hypothesis is rejected and the difference between the standard deviations is significant which means that the two samples under test cannot be supposed to be parts of the same population.
Example:
Prove that there is no significant difference between the standard deviations of the following two samples and they are drawn from the same population:



So the calculated value of F (= 2.14) is less than the tabulated value of F (= 3.10) at 11 and 9 degrees of freedom and 5% level of significance. So the Null hypothesis is accepted, i.e., there is no significant difference between the standard deviations of the two samples under test and they might have been drawn from the same population.
Example:
The data regarding the effects of two nutrients A and B on the increase in height of plants after 10 days of application have been presented in the following table. For nutrient A a sample of 12 plants and for nutrient B a sample of 10 plants were considered. With the help of F-test prove that there is no significant difference in the variances of the two samples at 5% level of significance.

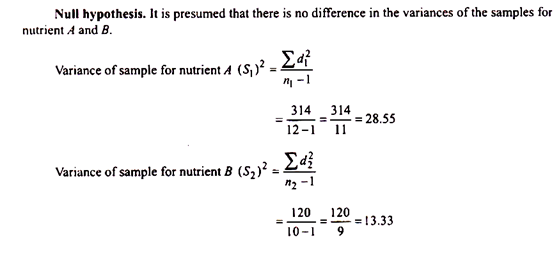

When the calculated value of F (= 2.14) is compared with the tabulated value of F (= 3.10) at 10 and degrees of freedom and 5% level of significance, it is apparent that F-cal is less than F-tab. fore, there is no significant difference in the variances of the samples for nutrient A and B at 5% f significance. Hence, null hypothesis is correct and accepted and the two samples appear to be: from the same population.
Test of Significance: Type # 3. Fisher’s Z-Test or Z-Test:
Z-test is based on the normal probability distribution and is used for testing the significance of several measures. The relevant test statistics is worked out and compared with its probable value (to be read; table showing the area under normal curve) at a given level of significance in order to judge the significance of measures concerned. Z-test is generally used to compare the mean of large sample; hypothetical mean for population.

Test of Significance: Type # 4. X2-Test (Chi-Square Test):
X2 square test (named after Greek letter x pronounced as ki) is a statistical method of testing significance which was worked out by Karl Pearson. Any biological study is based on a limited number of individuals which constitute a sample. A sample is a small part of population at random.
If a sample is drawn from population at random, each individual of the population is given equal opportunity to be included in sample and so the properties of samples will reflect the properties of population of which they are the part. Thus, the various statistics like mean, ratios, variance calculated from a random sample are estimates of those of parent population. The mean ratios variance of sample may be close but seldom equal those of parent population.
In a cross between tall and dwarf pea plants Mendel found 787 tall and 277 dwarf plants out of 1064 plants in F2 generation that yielded a ratio of 2.84 tall: 1 dwarf which was close to but numerically slight different from the expected ratio 3 Tall: 1 Dwarf from the imaginary population. Such deviations are bound to occur in all biological situations like this.
Thus, there should be some objective criteria to decide if a set of observed data is in accordance with specified or expected ratio. In other words, it is applied to test goodness of fit of the frequency of observed data with the expected or specified ratio.
X2-test is generally applied to enumeration data and rarely to measurement data and it involves the following steps:
1. Formation of a Null hypothesis:
In this, it is presumed that the observed data are not different from the specified or expected ratio, i.e., the deviation of observed data from the expected ratio is not real but is due to chance only.
2. Test statistics or computation of value of X2:
After the formation of null hypothesis, the deviation of observed data from the expected frequencies of different classes of data will be considered due to chance only. Calculation of the value of from observed data is made in the following way:
(i) The observed frequencies of different classes are arranged sequentially e.g., Tall 287 and Dwarf 277 in f2 generation of Tall x Dwarf.
(ii) The expected frequencies of different classes are calculated on the basis of expected ratio (as stated in the null hypothesis) and the total number of observed values. For example, the expected ratio of Tall to Dwarf is 3: 1 and the total number of observations is 1064 plants.
(This ratio specifies that out of every 4 (3 + 1), 3 (i.e., 3/4) will be tall and one (i.e., 1/4) will be dwarf plants. Therefore, out of total 1064 plants, three-fourth (or 1064 x 3/4) = 798 should be tall and one-fourth (i.e., 1064 x 1/4) = 266 should be dwarf plants.
Likewise in a dihybrid experiment involving Tall and red flowered x Dwarf, white flower the expected ratio for F2 plants is Tall Red: Tall, White: Dwarf, Red: Dwarf White:: 9: 3 : 3 :1.
If the total number of plants in F2 generation is 556, the distribution of frequencies for different classes will be calculated in the following way:

(iii) In the next step deviation of observed frequency from the expected frequency of each class is determined by subtracting the expected frequency from the observed frequency of the respective class (deviation = observed frequency – Expected frequency or d=o-e). The value of deviation may have either positive (+) or negative (-) sign.
Thus, in the above example of monohybrid cross, the deviation value for tall plants is 787 – 798 = -11 and that for Dwarf will be 277 -266 = +11.
(iv) Now the deviation value (d) of each class is squared to get all values in positive.
(v) The importance of a deviation depends on its magnitude as well as on the value of expected frequencies from which the deviation has occurred. Suppose that the magnitudes of deviations in two classes of data are equal, say 11 in monohybrid cross Tall x Dwarf but the expected frequencies of the two classes are different say 798 for one class (Tall) and 266 for the other class (Dwarf).
Thus there is disparity in the importance of deviations due to unequal expected frequencies of different classes of data. In order to remove this disparity, the deviation squares are divided by expected frequencies of the respective classes (o – e)2/e. All the numbers (quotients).
So obtained are based on the expected frequency of one and are, therefore, equal in importance.
(vi) X2 value:
The sum (total) of all quotients of different classes yields the calculated value of c square. Thus Chi Square may be defined as the total of the quotients obtained by dividing the deviation squares of different classes with their respective expected frequencies.
This is expressed as follows:

Degree of Freedom:
It is one less than the total number of classes and is expressed as d.f=n-1 where n= no.of classes.

(viii) Table value of X2:
It is obtained from X2 table (Table 3) at given degree of freedom and 1% (0.01) or 5% (0.05) level of probability. In Chi Square table maximum values of Chi Square at different probability levels and at different degrees of freedom obtained purely due to chance are listed which serve as points of reference while deciding whether the calculated value is due to real or chance deviation. The value of X2 depends on the variables, degree of freedom and probability.
(ix) Level of significance:
In X2 table probability is listed in top most row and is designated by P. The maximum values of X2 at different probability levels are recorded against different degrees of freedom.
The value of Chi Square as given in the X2 table against 1 degree of freedom at 5% (0.05) probability level is 3.84. This means that out of a large number of similar experiments with one degree of freedom, 5% or 0.05 experiments will show X2 value 3.84 or less than that only due to chance. Consequently in 0.95 or 95% of experiments X2 value 3.84 or of lower magnitudes will be due to real deviation of observed data from the expected data.
(x) Test of Hypothesis:
After determining the X2 value from observed data, the calculated value of X2 is compared with table value of X2.
There are two ways in which a conclusion may be drawn regarding the validity of null hypothesis:
(a) If the calculated value of X2 is less than the table value at 5% probability against given degree of freedom, the deviations of observed frequencies from the expected frequencies are not significant and are accepted to be purely due to chance. Therefore, null hypothesis is accepted and it is inferred that the observed data are in accordance with the expected ratio.
(b) If the calculated value of X2 is equal or greater than the table value of X2 at 5% level of probability and given degree of freedom, then the deviations of observed data from expected value are statistically significant. In such a case null hypothesis is rejected and it is concluded that observed data are not in accordance with the expected ratio.
The following example will clarify the procedure of X2- test.
Example:
In a cross between tall and dwarf plants Mendel found 787 tall and 277 dwarf plants in F2 generation. Using X2 –test find out the goodness of fit.
Solution:
Null hypothesis:
It is presumed that observed data are in ratio of 3 Tall: I Dwarf in f2 generation.

Degree of freedom = number of classes -1
= n – 1 = 2 – 1 = 01
considered level of significance: 5% or 0.05.
Table value of X2 at 1 degree of freedom and 5% level of probability obtained from X2 table is 3.84.
Test of significance:
On comparing the calculated value of X2 with table value of X2 it is clear that the calculated value (0.607) is less than the table value (3.84). So the deviation of observed data from the expected ratio is purely due to chance. Hence the null hypothesis is accepted and it is concluding that the observed data are in accordance with the expected ratio, i.e., they show goodness of fit with the expected ratio.
Example:
In a dihybrid cross between pea plants with round seeds and yellow cotyledons and those with wrinkled seeds and green cotyledons Mendel found 35 round, yellow; 108 round, green, 101 wrinkled , yellow and 32 wrinkled, green seeds in F2 generation. Find out the goodness of fit of observed data with expected F2 ratio 9: 3: 3: 1 by X2 – test.
Solution:
Null hypothesis:
It is presumed that the observed data are in accordance with the expected F2 ratio 9:3:3: I.

Table value of X2:
The value of X2 recorded in X2 table (Table 3) at 3 d.f. and 5% probability level is 7.815.
Test of Significance:
The calculated value of X2 from the given data is less than the table value of X2 at 3 d.f. and 0.05P indicating that the deviations are due to chance only and, therefore, null hypothesis is accepted and it is conclude that the data are in agreement with the expected ratio 9:3:3:1, i.e., observed F2 data show goodness of fit with the expected F2 ratio 9:3:3:1.
Yates Correction:
In the cases where only two classes exist and the frequency of one of the two classes is less than 50, Yates correction is applied to increase the precision of X2 – test. Yates correction is made by deducting or subtracting 0.5 from the deviations of the two classes. In the subtraction process the + or – sign of the deviation value is ignored. Thus the corrected deviations are 0.5 less than the actual deviation values.
The subsequent steps in calculation of from the corrected deviations and drawing conclusions are the same as discussed earlier.
The following example will illustrate the procedure of X2 test involving Yates correction:
Example:
In a cross between round seeds and wrinkled seeds, Mendel found 165 round seeds and 35 wrinkled seeds in F2 generation. State:
(i) What is the expected ratio in this case?
(ii) Null hypothesis.
(iii) Degree of freedom.
(iv) Correction required in this case.
(v) Carry out X2-test to ascertain if the observations agree with the expected ratio.
Solution:
1. The data presented in this problem indicate that the cross is of monohybrid nature and the expected in F2 generation is 3: 1.
2. Null hypothesis. It is presumed that the observed F2 data are in agreement with expected F2, ratio 3:1.
3. Degree of freedom (d.f.) = number of classes – 1
= n – 1 or 2 – 1 =01
4. Since the frequency of one of the two classes, i. e… Wrinkled seeds is 35, Yates correction could be applied in this case.
5. Calculation of X2 value from the observed data after Yates correction.
 Considered level of probability 5% or 0.05 P. The value of X2 recorded in table at 1 d.f. and 0.05 P level is 3.84.
Considered level of probability 5% or 0.05 P. The value of X2 recorded in table at 1 d.f. and 0.05 P level is 3.84.
Since the calculated value of X2 from the observed F2data is 5.621 which is more than the table value of X2 recorded at 1 d.f. and 5% level of probability. This indicates that the deviations of observed data from expected frequencies are real and significant. Therefore, the null hypothesis is rejected and it is concluded that observed data are not in agreement with the expected F2 ratio 3:1.