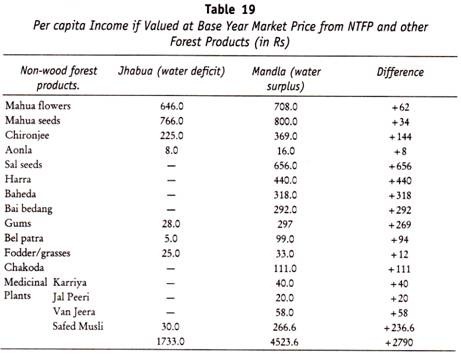
In this article we will discuss about Phenetic Versus Phylogen Characters in Taxonomy.
Phylogenetic Characters in Taxonomy:
Phyletic or Evolutionary or Phylogenetic characters are used primarily in phylogenetic classification. The term Phylogenetic is used in many ways.
Haeckel (1886) used the term in evolutionary history of a group. Recently a particular approach to classification (cladism) have used phylogentic to refer to reconstructing only the branching sequence of phylogeny. This approach is called cladistics with phylogenetics retained in its original and broader usage.
The character distinction is in between homologous versus analogous. Homologue means the same organ in different animals under every variety of form and function. Analogue means a part or organ in one animal which has the same function as another part or organ in a different animal.
After Darwin’s theory of evolution the homologous organs were viewed as structural modification of the same organ, inherited from a common ancestor. Analogues are those features developed by different organs to the same selection pressure.
The detection of homologus character is a difficult task for a phylogenetic reconstruction. Because of complexities, botanists have tended to deal with the problem obliquely.
Phylogentic and Ontagenetic characters are simply features which are presumed to reflect information about the phylogeny of the group; and developmental features. A regressive character is one in which loss of appendages occur. In context of evolution these are also known as adaptive or non-adaptive characters.
Phylogenetic classification attempt to reflect the geneology or evolutionary history of a particular group of plants.
Cladistic Characters:
The characters have developed from the cladistic approach to classification attempting to determine branching sequence of evolution and base a classification upon them. Only derived character states are regarded as significant cladistically.
Characters are Primitive vs. derived character states; or as synonyms, general vs. unique; generalized vs. Specialised, Primitive vs. advanced, Plesiomorphic vs. apomorphic and Pfesiotypic vs. apotypic etc. Plesiotypic and Apotypic terms were used by cladists like Wiley (1981), Wagner (1983) etc. Shared derived character states between and among the taxa are called synapomorphies (or synapotypies) and shared primitive states are symplesiomorphies (or symplesiotypies).
Automorphy:
Derived character state occurring only in one evolutionary line and has no direct use in constructing branching sequences.
Compatible character:
Useful cladistical characters are called compatible characters where evolutionary directionality of the states within each character is the same.
Problems with Phylogenetic Classifications:
i. Convergent Evolution:
Species with similar selection pressures look alike i.e., appear alike, and hence, can ‘trick’ a taxonomist.
ii. Lack of Fossils:
Fossilization is a sporadic process. Some events happened so quickly that fossils may not adequately document the changes i.e., the angiosperms appeared very rapidly in fossil records.
iii. Strict Evolutionary Classification:
It assumes a monophyletic origin of groups i.e., the ancestors can only came from one group; they cannot be polyphyletic e.g., the members of your immediate family i.e., grandparents, parents, siblings make up a group with a single origin (monophyletic). Neighbours are not included in this group since they have a different origin.
Logical Conclusion:
All angiosperms arose from a single common ancestor.
Phenetic Characters in Taxonomy:
An approach to biological classification which uses overall similarity to assess relationships is called Phenetics or numerical taxonomy. Phenetic classification makes no attempt to reflect evolution; taxa are related based on similarity and difference of character states regardless of the evolutionary content of the characters and states reflected. The character of choice in phenetics is the Unit character or Single character.
In phenetics each unit character is given the same or no weight while in phyletic and cladistic classification the weighting of character is believed to be evolutionarily important. Phenetic classification are based on overall similarities of characters.
Dendrogram:
It is branching diagram in the form of tree and depicts degree of relationship.
Phenogram:
It is representation of phenetic relationship.
Cladogram:
It is the depiction of cladistic relationship.
Modern Phenetic Methods (Taxometrics):
Phylogenetic classifications of plants faced many difficulties and uncertainties. It led to new method of classification with Phenetic approach instead of phylogenetic approach. It was given by Sneath and Sokal (1957).
It was a coincidence that numerical taxonomy has come to be almost synonymous with phenetic classification. Numerical taxonomy neither produces new data nor is a new system of classification but it is a new method of organizing data and obtaining from them a classification.
R.H.A. Sneath or R.R. Sokal published a textbook “Principle of Numerical Taxonomy” in 1963 and revised it in 1973 as Numerical Taxonomy. They have suggested seven main advantages of numerical taxonomy over conventional taxonomy.
These seven principles are as follows:
(1) The greater the content of information in the taxa of a classification and the more characters on which it is based, the better a given classification will be.
(2) A Priori every character is of equal weight in creating natural taxa.
(3) Overall similarity between any two entities is a function of their individual similarities in each of the many characters in which they are being compared.
(4) Distinct taxa can be recognized because correlation of characters differs in the group of organisms under study.
(5) Phylogenetic inferences can be drawn from the taxonomic structure of a group and from character correlations, given certain assumptions about evolutionary pathways and mechanism.
(6) Taxonomy is practiced as an empirical sciences as opposed to interpretative or intrutive science.
(7) Classification are based on phenetic similarity.
Most of these principles bear resemblance to the aims and methods of Adanson and are therefore, known as Neo-Adansonian principles.
Numerical Taxonomy is based on Phenetic evidences, i.e., on similarities by observed and recorded characters of taxa, and not on phytogenetic probabilities. Since, numerical taxonomy is operational in the sense, it is divided into a series of repeated steps, allowing its results to be checked back step by step.
The logical steps are:
(1) Choice and Number of units to be Studied:
First of all the kinds of units are to be selected. These units may be individuals, lines or strains, species etc. The basic unit of numerical taxonomy is operational taxonomic Unit (OTU). The term is given to the lowest term being studied in a particular investigation.
The number of characters needed to achieve are at least 60 characters or more like 80 or 100 as desirable. In listing characters only homologous characters be compared. Homology is usually defined on the basis of common evolutionary origin.
It is very impractical definition because of lack of evolutionary data. Practically one only guesses the homologies by making as detailed as possible an investigation of the structures concerned.
(2) Character Selection and Taxon Matrix:
Character is a feature of an individual or taxonomic group, which can be measured, counted or assessed. The kind of character used mostly depends upon the type of organisms being studied.
In angiosperms mostly morphological, physiological or distributional ones are used as OTU. The character is chosen by which they are to be classified. Each OTU has to scored for the possession of one or other character-state or attribute of each character; resulting in Data-matrix of attributes. (OTUs X characters or taxon).
If one is classifying 30 OTUs and using 100 characters the data matrix will consist of 3000 attributes. A computer is essential to calculate the data because of number and variety of operations.
The use of a computer necessitates the codification of the attributes in some simple form which can be feed into the computer, and this presents great problem. The simplest codification is a Binary or two state system, e.g., ± and – or 0 and 1 where each character exists in only two states.

+ = Attributes present, – = Attribute absent and ± = may be present in some species.
If the characters are many they may be multistate qualitative characters such as colour of Petals as white, yellow, red, blue, etc. or multistate quantitative characters such as amount of pigment/unit volume or number of hairs/unit area.

Cluster Analysis:
Data presented in OTUs x OTUs (t x t) matrix are much exhaustive and difficult to give correct picture. In cluster analysis the OTUs are arranged in order of decreasing similarity.
An acceptable data matrix is prepared for computer programme, using the matrix, the computer sorts out clusters OTUs according to their overall similarity. The final result in a hierarchial dendrogram of phenetic relationships (phenogram) in which less and less similar OTUs are successively linked together.
There are many different methods representing Taxonomic structure of the group of OTUs under study in an imaginary taxonomic, multidimensional space or hyperspace.
The clusters of OTUs recognized are defined by the possessions of the greatest number of shared features, i.e., they are polythetic.
Monothetic groups on the other hand are defined by the possession of unique set or feature which is necessary and sufficient to define the groups.
In numerical taxonomy the terms Phenon replaces taxon, i.e., rank of any level and the particular phenons are designated by numerical prefixes showing the level of resemblances by which they are defined.
50 phenon or 70 phenon means phenons defined by a 50 percent or 70 percent similarity in the attributes over which they were scored, and they are physically delinked by drawing horizontal straight lines or Phenon lines at the appropriate level across a phenogram.
There are many examples of numerical taxonomy solving taxonomic problems. Clifford (1977) studied Alismidae, Lilidae, Commelinidae, and Arecidae. On the basis of results of cluster analysis Alismidae was kept away from others.
According to Clifford Triuridales (In Alismatidae by Cronquist and Lilidae by Takhtajan) belong to distinct groups. Takhtajan (1997) separated Triuridales under sub class Tricididae. Throne (1992) placed it under distinct superorder Triuridanae. Takhtajan (1997) separated Arales into a subclass Aridae.
Young and Watson (1971) worked in dicots using 83 attributes in their analysis of 543 representative genera and proposed division of dicots into Crassinucellatae and tenuinucellatae.
There is a lot of criticism of numerical taxonomy since classifications produced by a computer are limited in value, since they rely upon a machine to make automatic calculation instead of sensitive judgment of the experienced taxonomist.
But to some extent this criticism is not accepted because computer performs the time consuming arithmetic only after the taxonomists used all their talent and decided the characters to be computed.
Equal weightage is given to all characters employed but infact the computer works out for us the character which should be weighed. If we weigh characters before they are fed into the computers, this implies that we know beforehand what the classification will be like.
Advantage of Numerical Taxonomy over Conventional Taxonomy:
(i) It has the power to integrate data from a variety of sources-, e.g., morphology, physiology, phytochemistry, embryology, anatomy, palynology, cytology, etc.
(ii) Automation of data processing promotes efficiency.
(iii) The data can be used for creation of description key, catalogue, maps etc.
(iv) It can provide better classification.
(v) Description can improve conventional taxonomy.
(vi) A number of evolutionary concepts are interpreted by this method.
Aims of Numerical Taxonomy:
Main aim is to determine phenetic relationship between organisms or Taxa. According to Sneath and Sokal (1973) phenetic relationship means similarity or resemblance based on a set of phenotypic characters. Cladistic relationship means expression of the recency of common ancestory and it is represented by branching network of ancestor-descendent relationship.
Calculation of Affinity:
The calculation of affinity between pairs of OTUs is based on some clearly stated statistics.
Sneath and Sokal (1973) recognized four basic types:
(a) Association coefficient.
(b) Distance coefficient.
(c) Correlation coefficient.
(d) Probabilistic coefficient.
(a) Association coefficient:
Pair functions that measure the agreement between pairs of OTUs over an array of two state or multistate characters. In this method binary data is used. Clifford and Stephenson (1975) made a chart showing different kinds of matching possible in one binary character between two taxa.
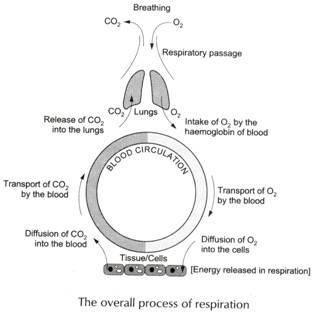
One of the earliest association coefficients used and easiest to comprehend for binary data is the Jaccard coefficient (Sj) given by Jaccard (1908) and Sneath (1957).
![]()
Jaccard’s coefficient:
It is a measure of the similarity in species composition between two communities. (A, B). It is calculated as
![]()
where c = number of species common to both, ‘a’ or ‘b’ = number of species occurring only in communities ‘A’ and ‘B’, respectively.
Simple matching coefficient (SSM):
It was given by Sokal and Michener (1958). Here also binary data is used. The sum of the positive (1, 1) and negative (0, 0) matches is divided by all possible matches.
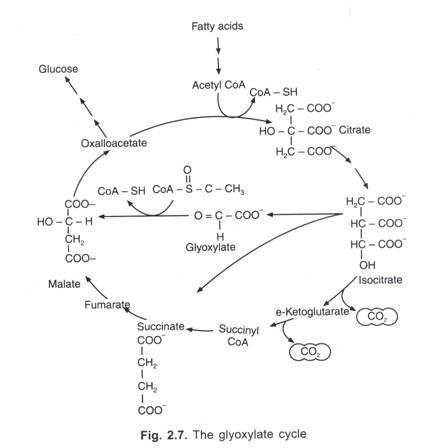
The coefficient is more effective with all positive attributes.
Gower’s General Similarity Coefficient (SG):
It was proposed by Gower (1971) and useful for binary, multistate, and Quantitative data.

Character i is shown between OTUs k and J. The weights (w) and scores (s) scores for each character in each OTU depends upon the nature of data, i.e., whether binary multistate or quantitative. It is flexible and useful coefficient for mixed data sets.
(b) Distance Coefficients:
It means the distance between OTUs in a space which can be defined in many ways. Distance coefficients are converse of similarity coefficients. They are infact the measures of dissimilarity.
Taxonomic distance is an expression of the relationship between individual or taxa in terms of multidimensional space, each dimension represents a character based on quantitative estimates of dis-similarity. It is depicted as ‘d’. It can be calculated in many ways.
Euclidean distance:
It is the simplest distance coefficient.

Xij is the character state value for character i and taxon J and Xik is that for taxon K. If all data are binary 0, 1, the values will be simply 0, 1 and -1, which when squared and square root taken, remove all negative numbers and the values of 1 or 0 for the distance between each pair of OTUs for each character.
Manhattan distance or Cit-block distance: It yields the absolute number of character state difference between two taxa:
![]()
Xij and Xik represents the values of the ith character for every pair of OTUs.
Crisci (1979) applied it, in many plant groups like Bulnesia, Zygophyllaceae etc. Farris (1970) and Nelson and Van Horn (1975) used it cladistic studies.
Mean character Difference:
It measures the absolute or positive values of the differences between the OTUs for each character. It differs from Dm by being divided by the maximum values of the character in the data set.
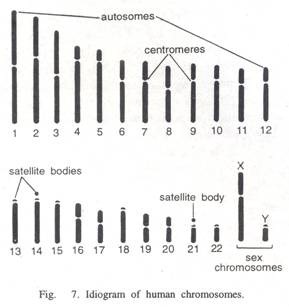
Coefficient of Divergence: In this the absolute character value difference between two taxa are divided by their sum, which give ratios between 0, and 1. Rhodes, Carmer, Courter (1969) used this in classification of cultivars of horse radish (Amoracia) of Brassicaceae.
(c) Correlation coefficient:
Frequently used in Phenetic studies as well as having been employed in phytosociology. Most common correlation is the Pearson Product-moment Correlation Coefficient.
Xij is the character state value of character i in OTUj, Xj is the mean of all state values of OTUs, and n is the number of characters sampled.
This correlation measure was used in Solatium nigrum complex (Solanaceae) by Soria and Heiser (1961). Oryza perennis (Poaceae) by Morishima (1969), in Melampodium (Asteraceae) by Stuessy and Crisci in 1984. This correlation is most useful where the data exists in more than two states.
(d) Probabilistic coefficient:
These are the complex coefficients not used frequently in phenetic studies. Goodall’s Similarity Index is designed to handle two state, multistate, and quantitative characters.
It is difficult to choose a method of coefficient. Sneath and Sokal favour use of binary data and a correlation coefficient which is suited to their comparison; because of its simplicity and possible relationship to information theory but also because, if the coding is done correctly, there is a hope that similarity between fundamental units of variations is being estimated.
Modern Phylogenetic Methods (Cladistics):
Wittering (1966) wrote a book called Phylogenetic Systematics, effectively founded the subject known as Phylogenetic systematics now called Cladistics. The term cladistics was coined by E. Mayr in 1969. Cladistics is a methodology that attempts to analyse phytogenetic data objectively, in a manner parallel to that in which taxometrics seeks to introduce objectivity into phenetics and Phenetic classification.
The methods of Wagner, Hennig etc., are known as Parsimony methods whereby they utilise the Principle of parsimony. Not only cladistics but phenetic taxonomists also used principle of Parsimony to relate extent OTUs without hypothesizing a priori. Cladistic methods differ fundamentally from taxometrics in the deductive (a priori) reasoning is used to determine routes of evolutionary change.
Hennig differentiated between Monophyletic, Paraphyletic and Polyphyletic groups and observed that taxa in a truly phylogenetic system should be only monophyletic. To identify monophyletic taxa, cladograms are constructed by considering primitive (Plesiomorphous) and advanced (apomor-phous) characters.
The possession of Plesiomorphous, character-states is common by a group of taxa and is known as symplesiomorphy, and the possession of derived character-state in common is termed synapomorphy. Fig.1.shows that symplesiomorphy does not necessarily indicate monophyly.
It is equally indicative of Paraphyly, (e.g., X and Y in B) Synapomorphy indicate monophyly, (e.g., Y and Z in A), but it can be polyphyly due to parallelism, (e.g., X and Y in C) or convergence, (e.g., X and Y in D). Such cases are known as false synapo- morphies. 
The basic units that are manipulated in cladistics are often known as evolutionary units (EUs), equivalent to the phenetic OTUs. Once a set of data relating to Plesimorphous versus apomorphous character-states has been accumulated for all the EUs, a data matrix can be constructed.
Cladogram is constructed based on the data. If the pairs of EUs are scored according to the number of differences in their respective character-states the table is formed which is called Manhattan distances which is in effect a dissimilarity matrix.
The dendrogram or cladograms are normally based upon the minimal or most parsimonious way in which the EUs can be connected to account for the data in the text table.
In case of fossils the cladogram are wholly hypothetical and are known together with the single hypothetical ancestor, as Hypothetical taxonomic unit (HTUs).
When the hypothetical ancestral taxon is known, the evolutionary polarity is decided rooted tree or dendrogram is formed. When polarity of characters is not decided, the dendrogram obtained is not directional, this is called Unrooted tree or network. Network can become rooted by deciding a posteriori.
Cladistic method basically views evolution as an ordered, divergent, step-wise transformation of characters from plesiomorphous to amorphous.
In 1977 the first symposium on cladistics for botanists was held at the AIBS meetings in EastLansing; Michigan. The proceeding of this published in 1978.
The second symposium was held in 1979 at the AIBS meeting in Stillwater, Oklahoma. As a result of disagreement between pheneticist and cladists the cladists established the new Willi Henning society and its first meeting was held in Lawrence Kansas (Birth place of phenetics).
There are many published books and literature on cladistics. To name some are:
(i) Problems of Phylogenetic reconstruction. Joysey and Friday (1982).
(ii) Methods of Phylogenetic reconstruction by Patterson (1982).
(iii) Cladistics Perspectives on the Reconstruction of Evolutionary History by Duncan and Stuessey (1984).
(iv) Cladistic Theory and Methodology by Duncan and Stuessey (1985).
(v) Phylogeny Reconstruction in Paleontology by Schoch (1986).
(vi) Biolocical Metaphor and Cladistic Classification by Hoesnigswald and Wienen (1987).
Methodlosy of Cladistics:
Depending upon the type of data and algorithms for the construction the procedure for cladistic analysis and classification varies.
Stuessy (1980) has given some conventional procedures, which are as follows:
i. Make evolutionary assumptions (select EUs, determine monophyletic grouping etc).
ii. Select characters of evolutionary interest.
iii. Describe and/or measure character states.
iv. Ascertain homologies of characters and character states.
v. Construct character state network.
vi. Determine polarity of character state network (primitive vs. derived conditions, i.e., root the character state network to form character to form character state trees. Group taxa based on synapmorphies.
vii. Construct basic data matrix.
viii. Select algorithm and generate trees (cladograms);
ix. Construct classification based upon cladograms.
x. Resolve the conflicts arisen by using some pre-defined method e.g., Parsimony.
xii. Build a tree following the rule like:
(a) All taxa go on the endpoints of the tree, never at the nodes.
(b) All nodes must have a list of Synamorphies, which are common to all the taxa above the node.
(c) All Synapmorphies appear on the tree only once, unless the character state was derived more than once through convergent evolution.
Convergence causes distortions in cladograms. This can be seen by the following phenomenon:
(a) Character-states arising by convergence are generally not logically correlated with other characters, and if a substantial number of characters is analysed those showing convergence are usually obvious.
(b) Parallelism and reversion, together termed Homoplasy; are less easily recognise. The presence of homoplasy means the correct cladogram might not be the one that appears to most parsimonious. Therefore methods depending on parsimony is less in these cases.
(c) Study of fossils led some cladists to use cladistics, i.e., Pattern or transformed cladistics merely to unravel to pattern of variation rather than detect the true geneology.
(d) Apart from parsimony methods other method is to utilize the concept of Character compatibility and is known as compatibility analysis or clique analysis. The method omits homoplasy.
Groups of mutually compatible characters are termed cliques. This represents a group of characters in which homoplasy is absent.
For example if two characters A; B are considered with two states A1 A2 and B1 B2 then the possible combinations are A1B1, A1B2, A2 B1 and A2 B2. The directional of evolution is A1 to A2 and B1 to B2, then if all four character state combinations are found in nature there must have been at least one reversal, i.e., A2 to A1 occurring twice. In this condition A and B are incompatible but if only 2 or 3 of the four combinations occur than A and B are compatible.
Goal of phylogenetic systematics is to understand the evolutionary relationships of all life on the planet and to reflect those relationships in a predictive classification.
Two related components are:
(a) Discovering relationships, and
(b) Developing a classification to communicate those relationships.
Phylogenetic tree diagrams:
Phylogenetic trees represent relative relationships between taxa. Tree diagram that seem to indicate directed character change or progress along the tips of the tree evolution produces a branching, tree like pattern of ancestor and descendent lineages-species alive today did not give rise to other species that are alive today.

Phylogenetic trees can be drawn in numerous ways, but it is always the relative position of taxa and their most recent common ancestors.

Reconstructing Phylogenetic Relationships Cladistics, methods, proposed by W. Hennin:
Based on recognition of clades: groups of organisms that descend from a common ancestor and shared derived characters.


Assumptions Characters:
(a) Heritable changes or mutations occur in lineage of reproducing organisms.
(b) Rate of mutation is greater than rate of cladogenesis or lineage splitting.
(c) Rate of mutation in characters is not so great as to swamp out evolutionary signal through multiple mutations back and forth in same character.
Vocabulary Characters:
(a) In cladistics, character can exist in two state.
(i) Derived apomorphic state
(ii) Ancestral plesiomorphic state.
(b) Shared derived character are known as Synapomorphies.
(c) Shared ancestral characters are known as Symplesiomorphies.
(d) Synapomorphy or Symplesiomorphy is relative and depends on the clade.
Difference between Organisms and their Characters:
(a) There are ancestral or primitive characters and derived or advanced characters in contrast no primitive or advanced organism.

(b) All organisms alive today have been evolving from the same length of time (from a common ancestor).
(c) Some organisms retain characters that are considered ancestral, but this does not mean that they are less evolved than others.
(d) Actually there are no “living fossil”.
(e) All life is descended from a single ancestor. So we can reconstruct relationships.
(f) Evolution proceeds through a process of bifurcation even i.e., one lineage always splits into two.
Parsimony:
Cladistic analysis depends on the principle of parsimony when selecting the best tree diagram to represent the relationships between the taxa at the tips.
(a) Parsimony assumes that the simplest solution is likely the best.
(b) In terms of tree diagrams, the most parimonious tree is the one that minimizes the number of character changes along the branches i.e., the less no. of steps the better parsimony.
Parsimony works well for morphological characters having multiple, complete character with relatively low rates of evolution.
DNA sequence data has only four (AGCT) possible characters leading to problems with tree reconstruction because it increases the likelihood of homoplasy.
Homoplasy means that the characters that look as identical through descent from a common ancestor, when in fact they are the same due to convergent evolution.
Major difference between Henning’s “Phylogenetic Systematics” and “Evolutionary Systematics” is that Henning’s classification only recognizes monophyletic groups. The taxa recognized in phylogenetic classification are based on their shared features and not on their differences with other taxa.
In 2000, the first draft of a purely phylogenetic code of binomial nomenclature (Phylocode) was released. Phylocode is a set of rules for naming Clades based on a phylogenetic hypothesis (tree).
(a) No ranks are associated with names.
(b) Clades are defined using “specifiers” which are reference organisms (analogous to type specimen).
(c) To define a clade, at least two specifiers are required along with their most recent common ancestors.
Under the Phylocode, clades are given a single name or it is universal it may be defined as
(a) Node base definition. ‘X’ is the clade containing all the descendents of the most recent common ancestors of A and B or ….E.
(b) Stem based definition:
‘X’ is the clade containing A and the all the organisms that ancestor with ‘A’ than with E (…Z)